如何在用户离开页面时可靠地发送 HTTP 请求
![]() 微wx笑
微wx笑 2022-07-03【前端开发】
2022-07-03【前端开发】
 4
4 0关键字:
HTTP请求
0关键字:
HTTP请求
HTTP在某些情况下,当用户执行诸如导航到不同页面或提交表单之类的操作时,我需要发送带有一些数据的请求以进行记录。
HTTP在某些情况下,当用户执行诸如导航到不同页面或提交表单之类的操作时,我需要发送带有一些数据的请求以进行记录。考虑这个在点击链接时向外部服务发送一些信息的人为示例:
<a href="/some-other-page" id="link">Go to Page</a><script>document.getElementById('link').addEventListener('click', (e) => {
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: "data"
})
});});</script>这里没有什么非常复杂的事情。该链接可以正常运行(我没有使用e.preventDefault()),但在该行为发生之前,会POST在click. 无需等待任何形式的响应。我只是希望它被发送到我正在访问的任何服务。
乍一看,您可能希望该请求的调度是同步的,之后我们将继续导航离开该页面,而其他一些服务器会成功处理该请求。但事实证明,情况并非总是如此。
浏览器不保证保留打开的 HTTP 请求
当浏览器中的某个页面发生终止时,不能保证进程中的HTTP请求会成功(请参阅有关“终止”和页面生命周期的其他状态的更多信息)。这些请求的可靠性可能取决于几件事——网络连接、应用程序性能,甚至外部服务本身的配置。
因此,在这些时刻发送数据可能并不可靠,如果您依赖这些日志来做出对数据敏感的业务决策,这会带来潜在的重大问题。
为了帮助说明这种不可靠性,我使用上面包含的代码设置了一个带有页面的小型 Express 应用程序。单击链接时,浏览器会导航到/other,但在此之前,会POST触发一个请求。
当一切都发生时,我打开了浏览器的网络选项卡,并且我使用的是“慢 3G”连接速度。一旦页面加载并且我已经清除了日志,事情看起来很安静:
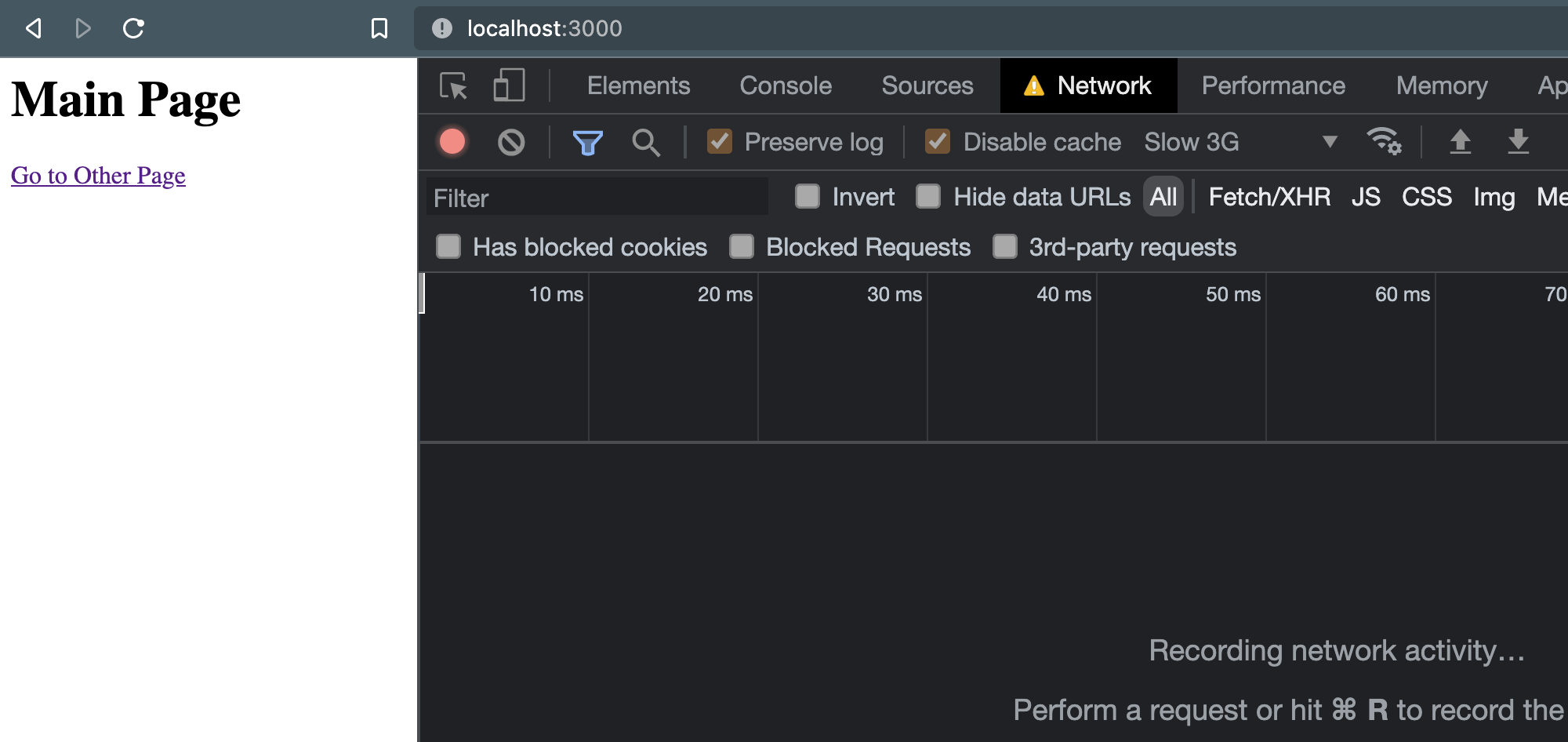
但是一旦点击链接,事情就会出错。当导航发生时,请求被取消。
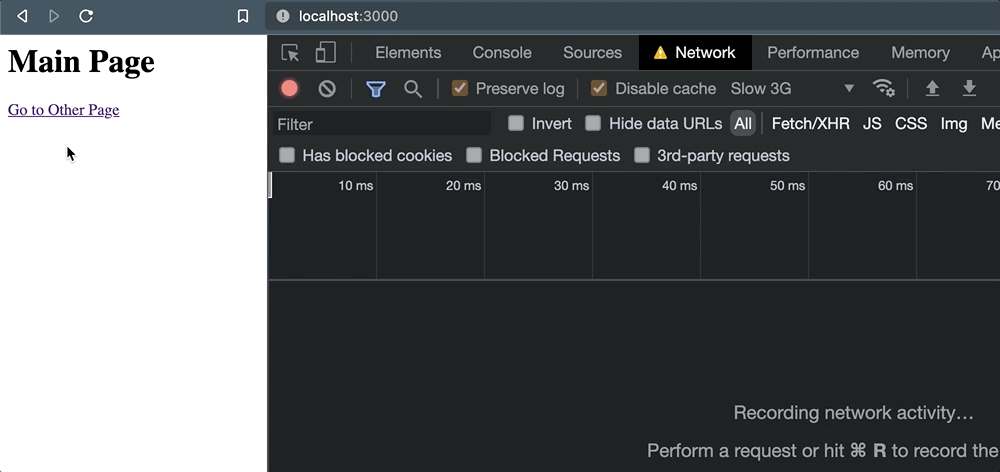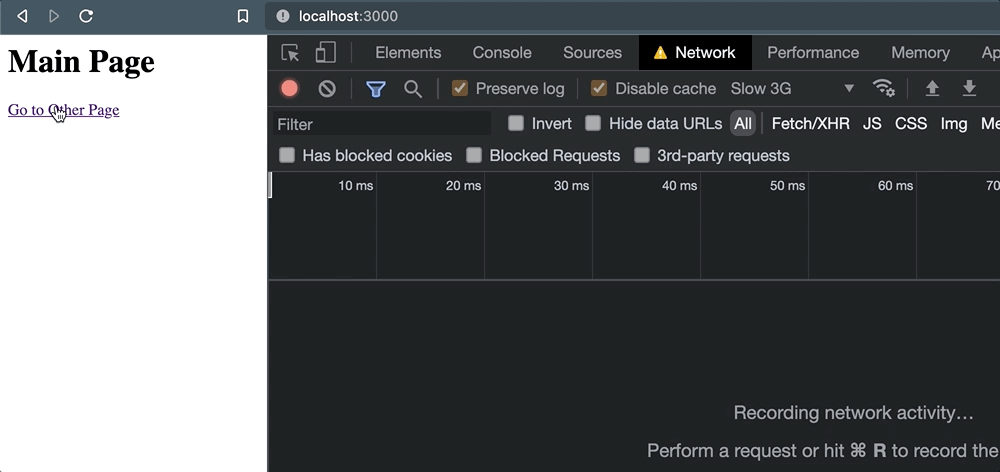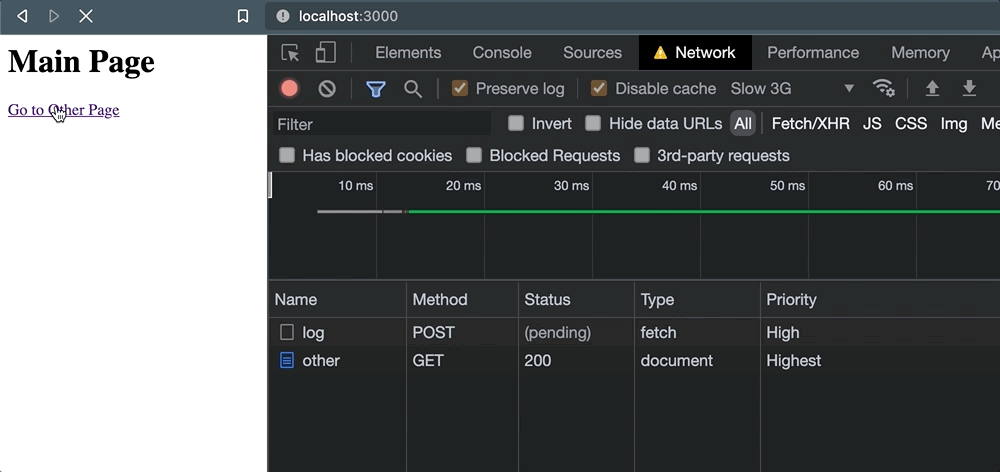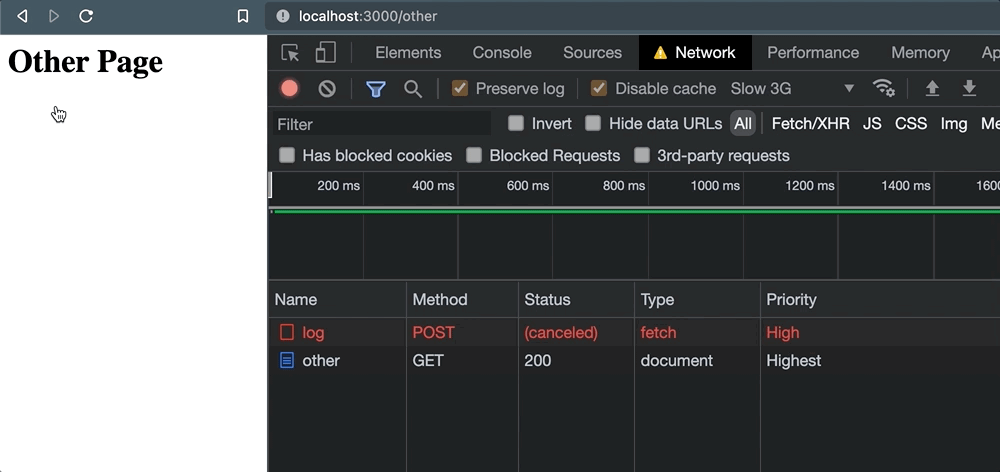
这让我们对外部服务实际上能够处理请求几乎没有信心。只是为了验证这种行为,当我们以编程方式导航时也会发生这种情况window.location:
document.getElementById('link').addEventListener('click', (e) => {+ e.preventDefault();
// Request is queued, but cancelled as soon as navigation occurs.
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: 'data'
}),
});+ window.location = e.target.href;});无论导航如何或何时发生并且活动页面被终止,那些未完成的请求都有被放弃的风险。
但是为什么他们被取消了?
问题的根源在于,默认情况下,XHR 请求(通过fetch或XMLHttpRequest)是异步且非阻塞的。一旦请求被排队,请求的实际工作就会被移交给幕后的浏览器级 API。
由于它与性能有关,这很好——您不希望请求占用主线程。但这也意味着当页面进入“终止”状态时,它们有被遗弃的风险,无法保证任何幕后工作都能完成。以下是 Google对特定生命周期状态的总结:
一旦页面开始被浏览器卸载并从内存中清除,页面就处于终止状态。在这种状态下没有新的任务可以启动,并且正在进行的任务如果运行时间过长可能会被杀死。
简而言之,浏览器的设计假设当一个页面被关闭时,没有必要继续处理它排队的任何后台进程。
那么,我们有哪些选择呢?
避免此问题的最明显方法可能是尽可能延迟用户操作,直到请求返回响应。在过去,这是通过使用支持的同步标志XMLHttpRequest以错误的方式完成的。但是使用它会完全阻塞主线程,导致许多性能问题——我过去已经写过其中的一些——所以这个想法甚至不应该被接受。事实上,它正在退出平台(Chrome v80+已经将其删除)。
相反,如果您要采用这种类型的方法,最好等待 aPromise在返回响应时解决。恢复后,您可以安全地执行该行为。使用我们之前的代码片段,可能看起来像这样:
document.getElementById('link').addEventListener('click', async (e) => {
e.preventDefault();
// Wait for response to come back...
await fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: 'data'
}),
});
// ...and THEN navigate away.
window.location = e.target.href;});这可以完成工作,但也有一些不小的缺点。
首先,它会延迟所需行为的发生,从而损害用户体验。收集分析数据肯定有利于企业(并希望未来的用户),但让你现在的用户支付成本来实现这些好处并不理想。更不用说,作为外部依赖项,服务本身的任何延迟或其他性能问题都会暴露给用户。如果您的分析服务超时导致客户无法完成高价值操作,那么每个人都会失败。
其次,这种方法并不像最初听起来那样可靠,因为某些终止行为不能以编程方式延迟。例如,e.preventDefault()在延迟某人关闭浏览器选项卡时没有用。因此,充其量只能涵盖为某些用户操作收集数据,但不足以全面信任它。
指示浏览器保留未完成的请求
值得庆幸的是,有一些选项可以保留绝大多数浏览器中内置的未完成HTTP请求,并且不需要损害用户体验。
使用 Fetch 的keepalive标志
如果在使用时将该keepalive标志设置为,则相应的请求将保持打开状态,即使发起该请求的页面已终止。使用我们最初的示例,这将使实现看起来像这样:truefetch()
<a href="/some-other-page" id="link">Go to Page</a><script>
document.getElementById('link').addEventListener('click', (e) => {
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: "data"
}),
keepalive: true
});
});</script>单击该链接并发生页面导航时,不会发生请求取消:
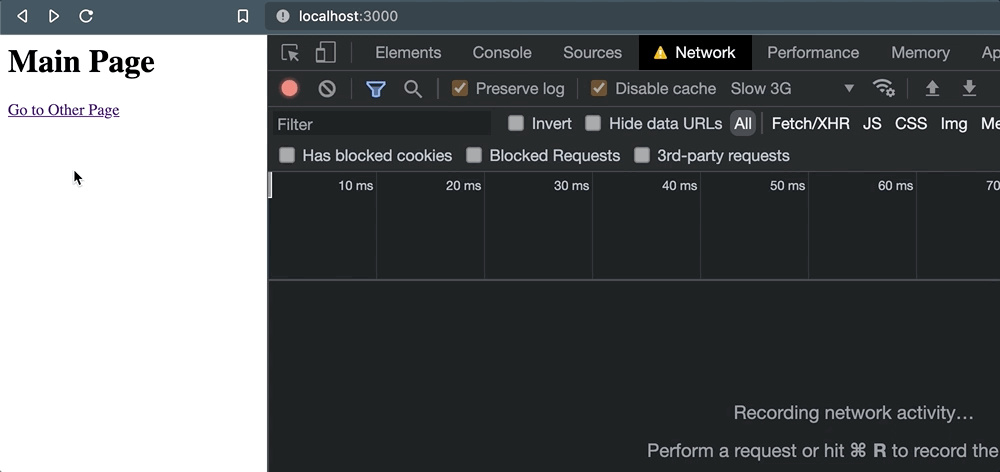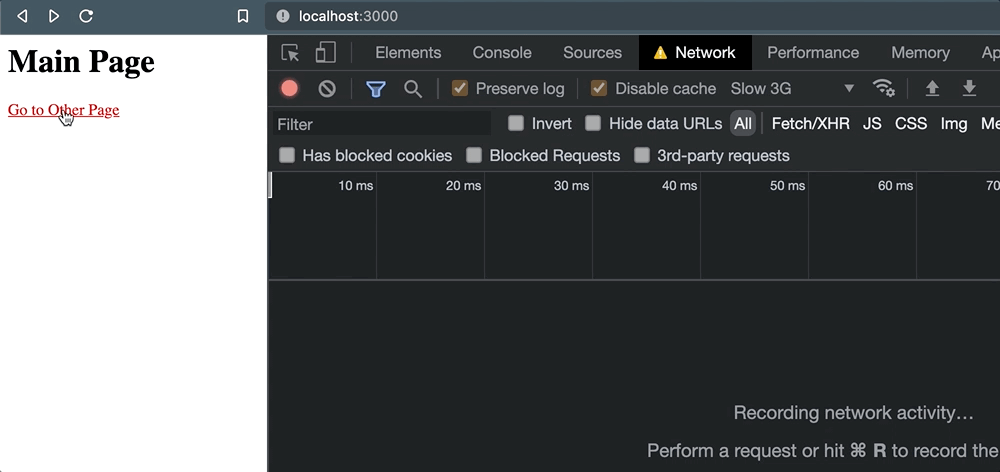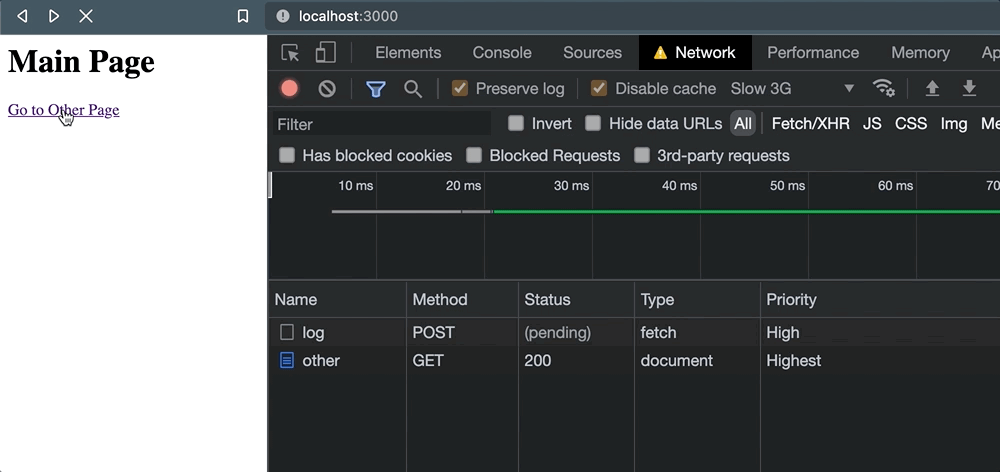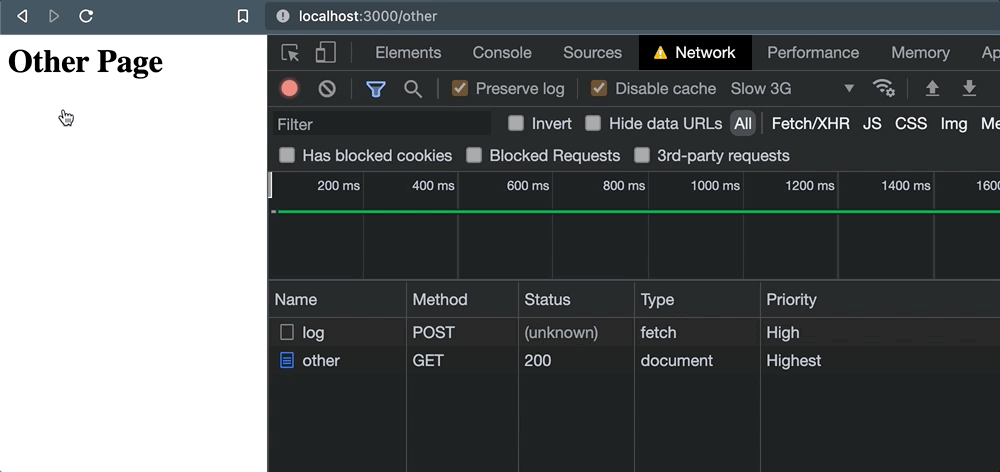
相反,我们留下了一个(unknown)状态,仅仅是因为活动页面从未等待接收任何类型的响应。
像这样的单行代码很容易解决,尤其是当它是常用浏览器 API 的一部分时。但是,如果您正在寻找具有更简单界面的更专注的选项,那么还有另一种具有几乎相同浏览器支持的方法。
使用Navigator.sendBeacon()
该Navigator.sendBeacon()函数专门用于发送单向请求(信标)。一个基本的实现看起来像这样,发送一个POST带有字符串化的 JSON 和一个“text/plain” Content-Type:
navigator.sendBeacon('/log', JSON.stringify({
some: "data"}));但是此 API 不允许您发送自定义标头。因此,为了让我们以“application/json”的形式发送数据,我们需要做一些小调整并使用Blob:
<a href="/some-other-page" id="link">Go to Page</a><script>
document.getElementById('link').addEventListener('click', (e) => {
const blob = new Blob([JSON.stringify({ some: "data" })], { type: 'application/json; charset=UTF-8' });
navigator.sendBeacon('/log', blob));
});</script>最后,我们得到了相同的结果——即使在页面导航之后也允许完成的请求。但是还有更多的事情可能会使其具有优势fetch():信标以低优先级发送。
为了演示,以下是同时fetch()使用keepalive 和 sendBeacon()时“网络”选项卡中显示的内容:
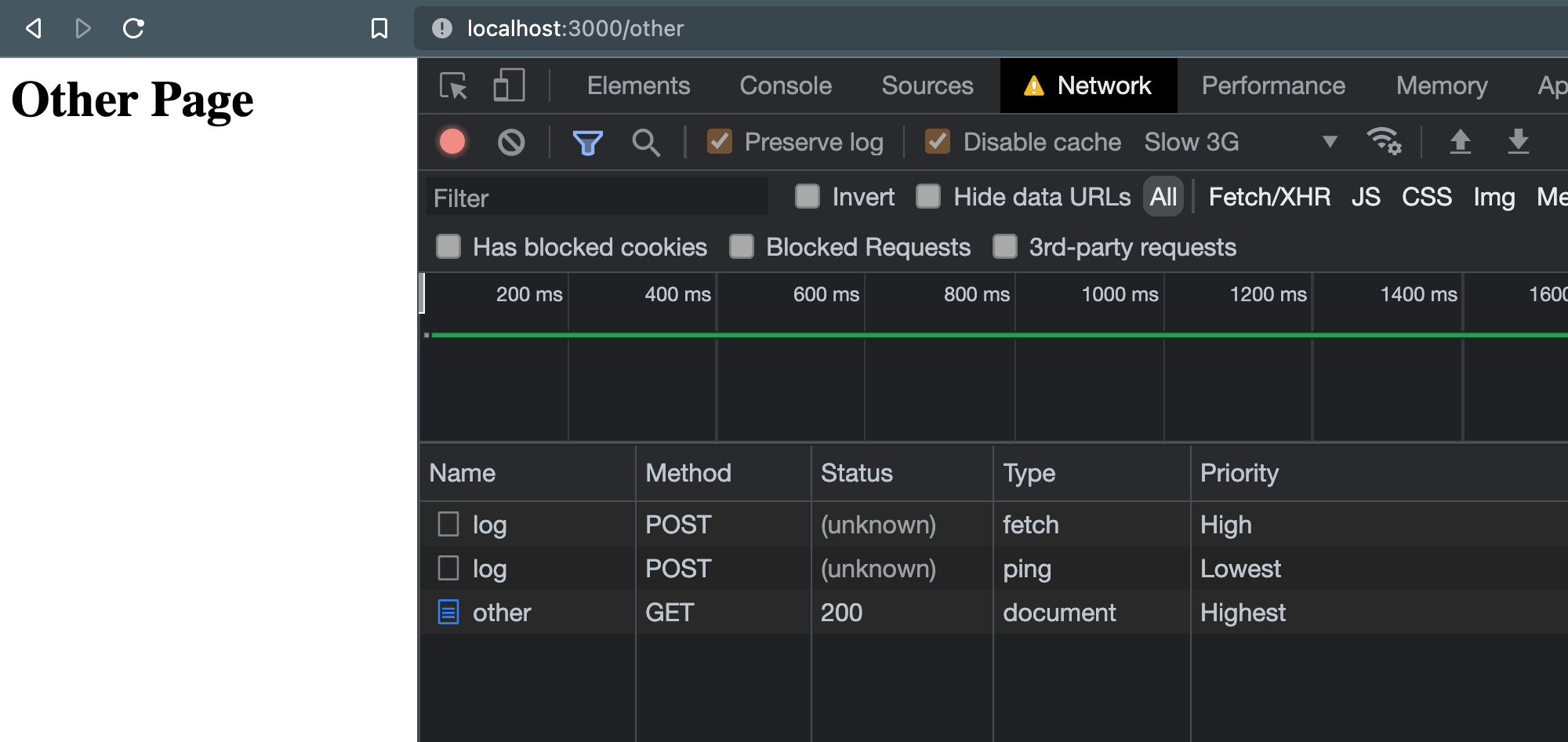
默认情况下,fetch()获得“高”优先级,而信标(上面称为“ping”类型)具有“最低”优先级。对于对页面功能不重要的请求,这是一件好事。直接取自Beacon 规范:
该规范定义了一个接口,[…] 最大限度地减少与其他时间关键操作的资源争用,同时确保此类请求仍被处理并交付到目的地。
换句话说,sendBeacon()确保它的请求不会妨碍那些对您的应用程序和用户体验真正重要的请求。
ping该属性的荣誉奖
值得一提的是,越来越多的浏览器支持该ping属性。当附加到链接时,它会触发一个小POST请求:
<a href="http://localhost:3000/other" ping="http://localhost:3000/log"> Go to Other Page</a>
这些请求标头将包含单击链接的页面 ( ping-from),以及href该链接的值 ( ping-to):
headers: {
'ping-from': 'http://localhost:3000/',
'ping-to': 'http://localhost:3000/other'
'content-type': 'text/ping'
// ...other headers},它在技术上类似于发送信标,但有一些明显的限制:
它严格限制在链接上的使用,如果您需要跟踪与其他交互相关的数据,例如按钮点击或表单提交,这将使其无法启动。
浏览器支持很好,但不是很好。在撰写本文时,Firefox 特别没有默认启用它。
您无法随请求一起发送任何自定义数据。如前所述,您将获得的最多的是几个 ping-*标题,以及其他任何标题。
综合考虑,ping如果您可以发送简单的请求并且不想编写任何自定义 JavaScript,那么它是一个很好的工具。但是,如果您需要发送更多实质内容,则可能不是最好的选择。
那么,我应该接触哪一个?
使用fetchwithkeepalive或sendBeacon()发送你的最后一秒请求肯定有权衡。为了帮助辨别哪种方法最适合不同的情况,需要考虑以下几点:
如果fetch():_keepalive
您需要轻松地通过请求传递自定义标头。
您想向GET服务发出请求,而不是POST.
您正在支持旧版浏览器(如 IE)并且已经fetch加载了一个 polyfill。
但sendBeacon()在以下情况下可能是更好的选择:
您正在发出不需要太多自定义的简单服务请求。
您更喜欢更简洁、更优雅的 API。
您希望确保您的请求不会与应用程序中发送的其他高优先级请求竞争。
避免重复我的错误
我选择深入研究浏览器在页面终止时如何处理进程内请求的性质是有原因的。不久前,我的团队在提交表单时开始触发请求后,发现特定类型分析日志的频率突然发生变化。这种变化是突然而显着的——与我们以往看到的相比下降了约 30%。
深入研究这个问题出现的原因,以及可以再次避免它的工具,挽救了这一天。所以,如果有的话,我希望了解这些挑战的细微差别有助于某人避免我们遇到的一些痛苦。快乐记录!
- 加比列拉拉萨瓦固定链接评论# 2022 年 2 月 23 日
服务人员对此非常有用。尤其是因为它可以访问所有 http 请求,从而允许它独立于 UI 代码记录它们。
- 瓒固定链接评论# 2022 年 2 月 24 日
不过有一件事,我上次尝试时,Beacon 在移动设备上不起作用:/
- 塞梅尔固定链接评论# 2022 年 3 月 23 日
{importance: "low"}在 fetch init 中需要 Chrome 101。
- 杰克梅森固定链接评论# 2022 年 6 月 27 日
不,sendBeacon() 正是用于从页面捕获最后时刻的分析数据。它最有可能在unload()中工作。如果没有,请使用beforeunload();这样可行。我通过在 timeonsite.js 库中测试这个 Beacon API 看到了它的工作原理;完全依赖 sendBeacon() 进行实时数据捕获。它似乎改变了游戏规则。
- 安迪戴维斯固定链接评论# 2022 年 4 月 9 日
有一个 Beacon 的提议,即使在 ATM 上工作的渲染正在消失,也可以保证交付
https://github.com/darrenw/docs/blob/main/explainers/beacon_api.md
- 杰克梅森固定链接评论# 2022 年 6 月 27 日
我认为这就是为什么像 timeonsite.js 这样的现代分析跟踪器完全依赖sendBeacon()而不是带有“sync”标志的 XMLHttpRequest 或带有“keepAlive”标志的 Fetch() API 的原因。对于浏览器中的所有类型的unload()事件,它似乎表现良好且高度稳定。https://saleemkce.github.io/timeonsite/docs/index.html#real-time-example
转自:https://css-tricks.com/send-an-http-request-on-page-exit/
注:这里有两个问题,
1、如果链接指向自己的网站,那么服务肯定能收到请求,为什么要单独的发送一个请求,而不是直接通过那个请求记录/分析?
2、如果链接的是外站,现在很多网站都是先跳转到自己的网站中的一个中间页面,然后再跳转,这样自己的网站也是可以记录的,为什么要单独的发送一个请求?
本文为转载文章,版权归原作者所有,不代表本站立场和观点。